Back-End Service Components
There are two questions when a back-end for a web server or a crawler is developed. First, how should the back-end process communicate with the front ends? From the perspective of the framework can be considered as answered because the .NET Framework itself has plenty of communication components (like WCF) to provide the architectural possibilities out of the box.
The second is harder to answer and quite annoying to implement: How should the back-end be hosted? There are several possiblilities too. For example: Hosting in the Web Server (so called IIS hosting), hosing in a Windows service, hosting in a Linux deamon, hosting in the cloud, integrate in the front-end or using a BaaS provider. These solutions have some things in common: They are propertiary, monolythic, unflexible and not very robust. And additionally when you develop directly for a cloud- or BaaS provider you are vendor locked with your hosting.
Additionally technical issues like this: Sometimes it happens that a back-end or worker process hangs. If this is a Windows service, Linux daemon or a process in the cloud the game is over. The Microsoft Internet Information Server have faced this and isolated his worker processes. A master process monitors them and terminates and restarts them when they are not working. So the process comes at least back and the operation can continue. But this is not very controllable and sometimes all worker processes disappear because the web site was idle for a longer time. It’s no solution for back-ends with a lot of background tasks.
Crawler-Lib Framework Services
The Crawler-Lib Framework Services designed to develop Windows Services, Linux Deamons and Cloud hosted services with ease. Thea are a clear alternative to Backend as a Service (Baas) providers, because there is no technology and vendor lock in for the hosting.
You decide yourself where your back-end service should be hosted.
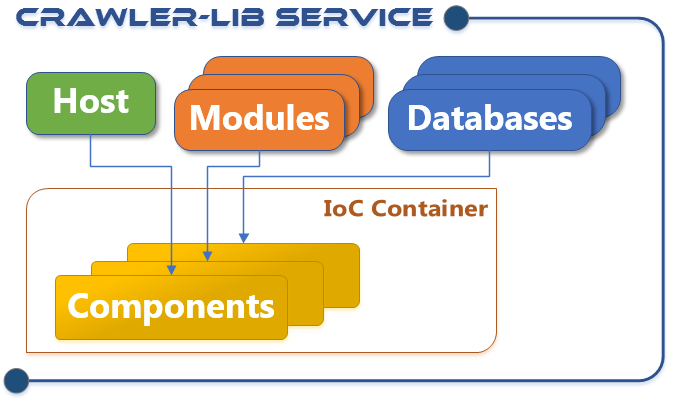
This is the beginning of a series of articles what this service infrastructure is and how to use it: