The Back-End Service Components are designed to allow to code back-end services that can be flexible hosted as windows service, Linux demon and in the cloud. But they allow also to test and debug services on the local machine in a uncommon way. It is a flexible middle way between monolithic hard coded back-end services and back-end as a service (BaaS) providers. Backend as a Service and Software as a Service providers couple couple two things that are very different: Modularization of the back-end and the hosting of the back-end. The Crawler-Lib service infrastructure prevents from a hosting provider lock in. It just brings the benefits of modularization and configuration to the back-end development. You choose the hosting of your back-end yourself.
Structure and Building Blocks
The service is build with several components and completely configured with the App.config configuration file. The idea behind this is to develop a service on the developer machine without to worry about deployment and hosting.
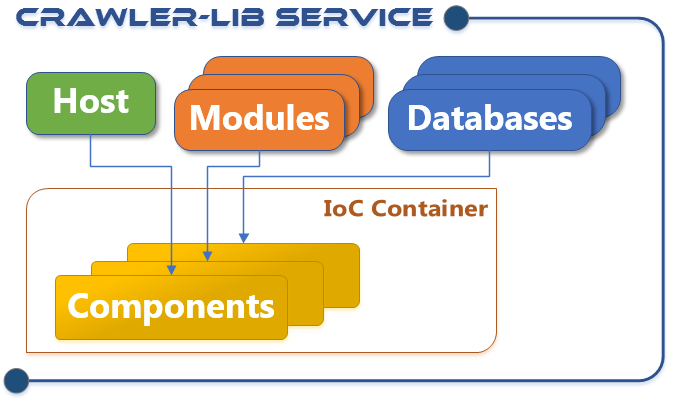
Hosts
The flexible configuration of hosts allows to deploy the service in different ways. There is a Windows Service host, a Linux demon host and cloud hosting is also possible. But more important, there is a WinForms Service Testing Host (NuGet package) which allows to set up a development and testing environment with ease.
Modules
The service infrastructure is designed to use service modules as composition block. As a user and developer you divide your back-end service into modules. Several predefined modules are in the release chain. Most important the Crawler-Lib Engine module, which integrates generalized task processing capabilities in the back-end service. But also a generalized WCF host to set up WCF endpoints just in the configuration. Standardization of additional back-end components will follow.
Databases
In conjunction with an upcoming storage operation processor the databases are the encapsulation and massive performance optimization of any kind of storage in a back-end service.
Components
Inversion of Control is used to decouple the service components. During the service startup the modules and database are wired. The modules and databases register its types and instances in certain phases of the service startup and resolve the needed components in a later phase. So the modules are containers for components.
Development
In classic service development the service itself is often monolithic and contains huge functionality in just one DLL or executable. The Crawler-Lib Service approach is similar to decoupled patterns often used in front-ends and BaaS platforms. It encourages the developer to divide the service functionality in small components and assemble them in handy modules with a exact specified functionality.
The most important change to classical service development is that the functionality is integrated in form of basically independent modules which provide and consume components. The infrastructure for a new service project is simply added as NuGet packages into a class library project in Visual Studio. Due to the component oriented infrastructure and the modularization non trivial projects should be split in several components and modules. This is both: Architectural structuration and a smooth way to put large or multiple teams on the project. It is very agile and supports also a wide range of project management and development mythologies like Test Driven Development, Scrum and so on.
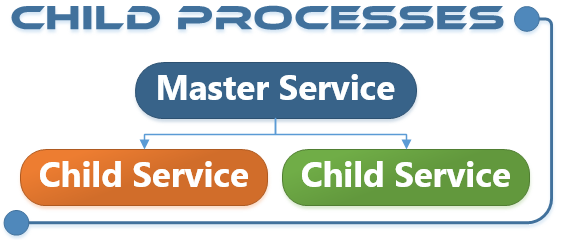
Different concepts can be combined to build a flexible infrastructure. For example child processes are integrated by default. This allows a master service so start and control child services. This can be used to separate critical components from the master process, to stop and restart child processes when they crash or when they are no longer needed. The mixing of 32Bit and 64 Bit processes is also possible to use legacy 32Bit components.
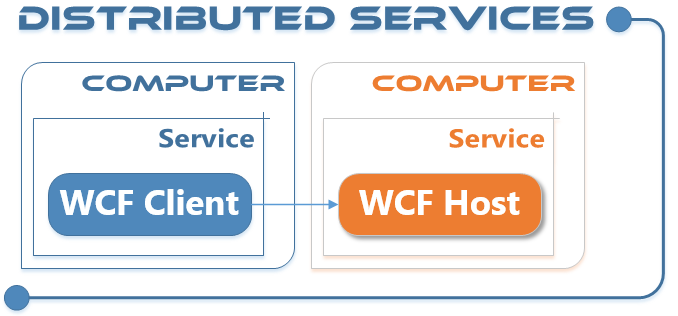
Distributed services can be easily implemented using WCF. As mentioned a full featured WCF host module and a matching WCF client component are already in the release pipeline. So it will becaome easy to develop distributed computing back-ends like rendering farms or crawler farms.
Testing
Due to the flexible hosting capabilities it is easy to test a service. As mentioned above Crawler-Lib provides the Service Testing Host which is a console host with a WinForms GUI testing frontend. It allows to interact with the running service and trigger functions and test code. This is especially important when a complex service has a very long startup time. Instead of starting the service over and over again to test some functionality, we can edit and execute C# test code while the service is running.
There is also no need to upload you service to any platform for testing purposes. Testing is possible on the developer machine or on a continuous integration server.
Deployment
Like other .NET applications the service deployment is mainly XML configuration (App.config) and XCOPY deployment. A little integration stuff must be done on the platforms, like installing a windows service or adding the demon to the Linux startup. This can be done with using the platform specific tools like PowerShell or BASH. In the future we will provide packages for this which can be installed with the platform specific package tools like a Chocolatey, APT (apt-get) or the upcoming OneGet (Windows Management Framework 5.0).